
Ongoing Projects
Here you find a selection of ongoing research projects at the Biodiversity Data Lab.
BIOSCANN - BIOdiversity Segmentation and Classification with Artificial Neural Networks
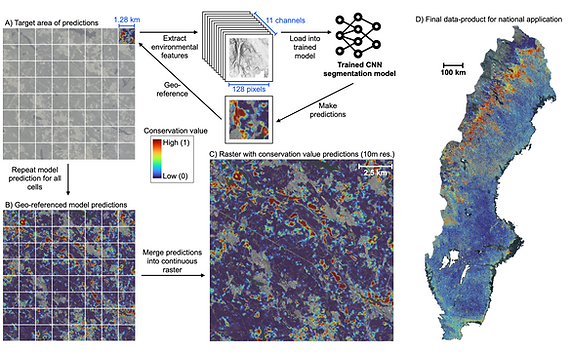
BIOSCANN implements a deep-learning segmentation model that integrates multiple layers of environmental data—satellite images, airborne laser scanning, and soil information—to identify forests of high biodiversity value in Sweden. With this approach we produce a national data product for Sweden with high-resolution biodiversity predictions.
View the interactive data product here.
You can find the project's GitHub page here.
News: Now the preprint is available here.
High-resolution insect diversity predictions from DNA-based monitoring
_edited.jpg)
We predict the expected insect biodiversity across Sweden at 10-m resolution using models trained on DNA data gathered from Malaise-traps (203 traps, 100 sites). The models integrate these biodiversity data with high-resolution environmental layers such as land cover, vegetation structure, hydrology, and climate. Presences and absences for each of the 11,000 insect species in our dataset were modeled in a joint species distribution model (jSDM) that estimates species-level occupancy while sharing information across taxa, improving inference for rare and sparsely detected species. We produced nationwide richness maps as well as species-specific probability maps (species distribution maps) at scales relevant for local management decisions. This jSDM-eDNA framework delivers scalable, and standardized biodiversity monitoring at management-relevant spatial resolution.
Limits to prediction: Why global biodiversity models fail to generalize

This project investigates the predictive accuracy of large-scale biodiversity models. Using a global dataset of 25,987 sites from 681 studies, we evaluate linear mixed models and Bayesian hierarchical models for alpha and beta diversity. The models are tested on their interpolation and extrapolation capabilities, revealing clear limits to prediction. Our results expose fundamental data limitations and underscore the need for large-scale data collection, model validation, and development of robust macroecological models.
Environmental Data Downloading Pipeline. A Python package for automated environmental data retrieval in ecological modelling

This project aims to develop a geospatial data downloading pipeline designed to accelerate ecological research by providing an easy-to-use and flexible service for feature extraction. It functions as a powerful intermediary between different repositories, such as the Google Earth Engine (GEE), and downstream predictive modeling applications. The service gives users granular control over data synthesis, allowing them to efficiently download geospatial information from multiple sources, including long-term climate records, high-resolution satellite imagery, and static geophysical maps. The end product can be delivered in two different formats: as summary statistics in tabular data or as raw raster images, all accurately clipped and projected for any defined area or sample point across the globe. Our automated data extraction tool cuts the time dedicated to cumbersome data acquisition, letting the user to focus their expertise on discovery and generating insight.